Programming Constructs
Juttle supports several programming constructs that are similar to other programming languages and make it easier to write and compose Juttle flowgraphs.
If you already know JavaScript and UNIX command-line tools, then elements of of Juttle will look familiar to you. Functions, variables, if statements, and other elements of the Juttle syntax are similar to their JavaScript equivalents. At the same time Juttle also borrows elements from UNIX command-line tools, with pipes and options that look like -option arguments to shell programs.
Constants
You can write constants in Juttle and use them in context within the flowgraph. By their nature, constants can't be assigned to or modified after being defined.
Juttle uses lexical scoping, so constants are scoped to the context in which they're written.
For example:
const n = 10;
emit -limit n -from :0: | reduce count() | view table -title "10 points";
const n2 = n * n;
emit -limit n -from :0: | reduce count() | view table -title "100 points";
Functions
A Juttle function performs a calculation based on provided inputs and returns a single result. Juttle comes with some built-in functions exposed through the built-in modules, and you can also define your own functions.
A function can operate over any number of arguments, and can be invoked with literals, variables, or field values as the arguments to the function.
For example, the following computes a point count and the square of the point count using the function Math.pow:
emit -limit 10
| put num_points=count(),
points_squared=Math.pow(num_points, 2),
points_cubed=Math.pow(num_points, 3)
Users can define their own Juttle functions, using the function keyword. The syntax is similar to JavaScript functions, although parameters can be given default values.
function functionName(parameter1[=default_value1], parameter2[=default_value2]...) {
code to execute
}
Functions can contain variable or constant declarations, assignments, if statements, and return statements. Juttle functions can also be nested by declaring one function inside another function.
For example, the following is a recursive implementation of Math.pow with a default exponent of 2:
function pow(value, exponent=2) {
if (exponent == 1) {
return value;
} else {
return value * pow(value, exponent - 1);
}
}
emit -limit 10
| put points=count(),
points_2=pow(points), // default exponent = 2
points_3=pow(points, 3)
Reducers
Reducers are a Juttle-specific construct that allows operating on field values of data points as they stream through the flowgraph, to carry out a running computation.
Reducers are used in reduce and put assignment expressions.
Juttle comes with a number of built-in reducers, including count(), sum() and max() used in this example:
emit -from :0: -limit 10
| put value = count()
| reduce sum = sum(value), largest = max(value)
Users can define their own reducers using the reducer keyword. To understand how reducers function, see User-defined reducers section that gives an annotated example.
Variables
Variables can be defined inside reducers and functions, but not inside subgraphs or at the top level of a flowgraph. Since Juttle uses lexical scoping, variables are scoped to the reducer or function in which they're defined.
Unlike constants, variables support assignment after they are defined:
For example:
const x = 5;
function xplus(y) {
var z = x;
z = x + y;
return z;
}
emit | put value=xplus(10);
String Templating
Strings in Juttle support template syntax to enable embedded expressions to be evaluated and converted to a string more conveniently.
The syntax for embedded expressions is ${expression}, where the referenced expression can be a constant, variable, literal, a value from a field in the point, or the result of an expression.
For example, the following juttle builds the same text string using both templating and manual construction of the string values.
const N = 10;
emit -limit N
| put text1="point ${count()} of ${N}, elapsed time ${time - :now:}"
| put text2="point " + Number.toString(count()) + " of " + Number.toString(N) +
", elapsed time " + Duration.toString(time - :now:);
Modules
Juttle modules are a way of reusing code across multiple Juttle programs.
Exporting symbols
Any saved juttle program can be used as a module if it exports functions, constants, inputs, subgraphs, or reducers by prefixing them with the export keyword.
For example:
export const answer = 42;
export function ask(question) { return answer; }
export sub elucidate { put a = answer }
export reducer answerable(q) { /* ... */ }
Importing modules
Given a juttle program containing exported symbols that is saved at a known
location, then in another program you can import it as a module, using the
import keyword:
import "<module_path>" as local_name;
<module_path> can either refer to a user import or a system
import.
User imports are references to individual modules. User imports can
either be a url, a full pathname starting with /, or a relative
pathname starting with ./ or ../. All other paths are considered
system imports.
When resolving user imports with relative pathnames, the pathname is always applied relative to the file doing the import. See the below examples for details.
System imports load predefined modules from standard locations. Examples of system imports are the Juttle Standard Library or adapter modules. For system imports, module_path is a path suffix that is combined with one of the standard locations to result in a full pathname.
For both user and system imports, when referring to files, a .juttle
extension will be added if not present, and when referring to
directories, an /index.juttle will be added.
Once it is resolved, the import statement pulls all exported symbols from the specified Juttle module and makes them available under the specified local namespace.
You can reference the imported symbol(s) like this:
local_name.symbol_name
- local_name is the local name from the import command above.
- symbol_name is the name of the exported subgraph, constant, function, or other code fragment from the imported program file.
Module Behavior
When defining or importing modules:
-
An
importorexportstatement is only valid in the top-level context of a program. This means that an import or export statement cannot be used inside subgraphs, functions, or reducers. -
Cyclic module dependencies are forbidden. For example, a compilation error occurs if module1 imports module2 and module2 also imports module1.
-
Top-level flowgraph statements are not exported, instantiated, or executed upon module import.
In the first example above,
emit | stamper -mark "test"is not exported.
Example: export from module
This juttle module exports a function, a subgraph, and a constant.
export const pi = 3.14; // exported constant
const not_exported = 2; // not exported
export function double(x) { return x * not_exported; } // exported function
export sub stamper(mark) { // exported subgraph
put stamp = mark
| put stamp2 = mark
}
// top-level flowgraph is not exported
emit
| stamper -mark "test"
| view table;
Example: user import by filename
This example assumes that the program with exports is saved at path
docs/examples/concepts/export_module.juttle, and that the program
being run is at docs/examples/concepts/import_module.juttle.
// This program is runnable from CLI from the juttle repo root,
// juttle docs/examples/concepts/import_module.juttle
import './export_module.juttle' as my_module;
emit
| my_module.stamper -mark 'test'
Example: modules importing modules with relative paths
This example uses the following files:
docs/examples/concepts/import_module_nested.juttle:
// This program is runnable from CLI from the juttle repo root,
// juttle docs/examples/concepts/import_module_nested.juttle.
import "./shared/module.juttle" as mod;
emit -limit 1 | put val=mod.myvalue | view table;
docs/examples/concepts/shared/module.juttle:
import './second_module.juttle' as mod2;
export const myvalue=mod2.value;
docs/examples/concepts/shared/second_module.juttle:
export const value = 10;
Example: import by URL
This example assumes that the exported module is saved as a
github gist
containing main.juttle file.
// This program is runnable from CLI from the juttle repo root,
// juttle docs/examples/concepts/import_module_from_url.juttle
import 'https://gist.githubusercontent.com/jut-test/273396ac4efcc838687b/raw/dde7c96c7560c38a29881d0345fc2d5727ee082e/main.juttle'
as this_module;
emit
| this_module.stamper -mark "test"
Example: using system import
This example loads the file random from the juttle standard
library. Note the use of the implied .juttle extension that is added
when resolving.
// This program is runnable from CLI from the juttle repo root,
// juttle docs/examples/concepts/import_module_from_stdlib.juttle
import "random" as random;
emit -limit 3 -from :0:
| put pure = random.normal(0, 1)
Example: adapter modules
This example loads the file aggregations.juttle from the aws
adapter. Note the use of the implied .juttle extension in the import
statement.
import "adapters/aws/aggregations" as Adapter_aws;
read aws product='EC2'
| Adapter_aws.aggregate_EC2
| filter demographic='EC2 Instance Type'
| keep demographic, name, value
| view table
Subgraphs
Subgraphs are reusable Juttle fragments that can be invoked within the current program or exported as modules that other programs can import.
Subgraphs are declared with the sub keyword, like this:
sub sub_name([arg1,arg2]) {
juttle code
}
A subgraph can take as many arguments as it needs, or none.
Example: simple sub with no arguments
// declare a subgraph called "my_viz" with no params
sub my_viz() {
put num_points = count()
| (view table; view timechart)
};
emit -limit 2
| put message = "Hello World!"
| my_viz; // invoke the subgraph here
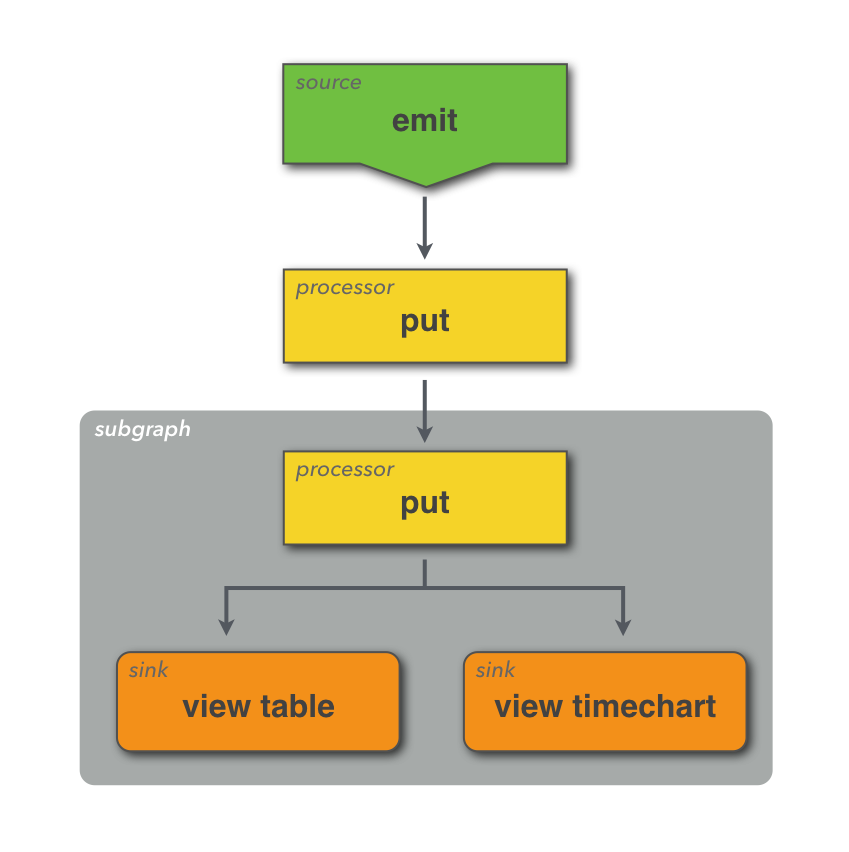
With this approach, experienced coders can express complex business logic and rich visualizations, then make them available to other Juttle authors to reuse.
Example: sub with optional argument
Here the default value will be used if the program that invokes the subgraph does not specify a different value:
sub banner(title='Generic title') {
emit -limit 1 | put value=title | view tile -timeField '';
}
banner -title 'Custom title';
See Field referencing for tips on working with the contents of fields from within a subgraph.